Smith normal form
In mathematics, the Smith normal form is a normal form that can be defined for any matrix (not necessarily square) with entries in a principal ideal domain (PID). The Smith normal form of a matrix is diagonal, and can be obtained from the original matrix by multiplying on the left and right by invertible square matrices. In particular, the integers are a PID, so one can always calculate the Smith normal form of an integer matrix. The Smith normal form is very useful for working with finitely generated modules over a PID, and in particular for deducing the structure of a quotient of a free module.
Contents |
Definition
Let A be a nonzero m×n matrix over a principal ideal domain R. There exist invertible 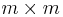 and
and 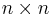 -matrices S, T so that the product S A T is
-matrices S, T so that the product S A T is

and the diagonal elements 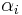 satisfy
satisfy 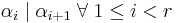 . This is the Smith normal form of the matrix A. The elements are unique up to multiplication by a unit and are called the elementary divisors, invariants, or invariant factors.
. This is the Smith normal form of the matrix A. The elements are unique up to multiplication by a unit and are called the elementary divisors, invariants, or invariant factors.
Algorithm
Our first goal will be to find invertible square matrices S and T such that the product S A T is diagonal. This is the hardest part of the algorithm and once we have achieved diagonality it becomes relatively easy to put the matrix in Smith normal form. Phrased more abstractly, the goal is to show that, thinking of A as a map from 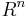 (the free R-module of rank n) onto
(the free R-module of rank n) onto 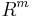 (the free R-module of rank m), there are isomorphisms
(the free R-module of rank m), there are isomorphisms 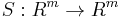 and
and 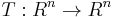 such that
such that 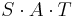 has the simple form of a diagonal matrix. The matrices S and T can be found by starting out with identity matrices of the appropriate size, and modifying S each time a row operation is performed on A in the algorithm by the same row operation, and similarly modifying T for each column operation performed. Since row operations are left-multiplications and column operations are right-multiplications, this preserves the invariant
has the simple form of a diagonal matrix. The matrices S and T can be found by starting out with identity matrices of the appropriate size, and modifying S each time a row operation is performed on A in the algorithm by the same row operation, and similarly modifying T for each column operation performed. Since row operations are left-multiplications and column operations are right-multiplications, this preserves the invariant 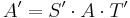 where
where 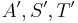 denote current values and A denotes the original matrix; eventually the matrices in this invariant become diagonal. Only invertible row and column operations are performed, which ensures that S and T remain invertible matrices.
denote current values and A denotes the original matrix; eventually the matrices in this invariant become diagonal. Only invertible row and column operations are performed, which ensures that S and T remain invertible matrices.
For a in R \ {0}, write δ(a) for the number of prime factors of a (these exist and are unique since any PID is also a unique factorization domain). In particular, R is also a Bézout domain, so it is a gcd domain and the gcd of any two elements satisfies a Bézout's identity.
To put a matrix into Smith normal form, one can repeatedly apply the following, where t loops from 1 to m.
Step I : Choosing a pivot
Choose jt to be the smallest column index of A with a non-zero entry, starting the search at column index jt-1+1 if t > 1.
We wish to have 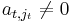 ; if this is the case this step is complete, otherwise there is by assumption some k with
; if this is the case this step is complete, otherwise there is by assumption some k with 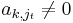 , and we can exchange rows
, and we can exchange rows 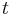 and k, thereby obtaining .
and k, thereby obtaining .
Our chosen pivot is now at position (t, jt).
Step II : Improving the pivot
If there is an entry at position (k,jt) such that 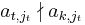 , then, letting
, then, letting 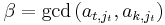 , we know by the Bézout property that there exist σ, τ in R such that
, we know by the Bézout property that there exist σ, τ in R such that
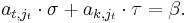
By left-multiplication with an appropriate invertible matrix L, it can be achieved that row t of the matrix product is the sum of σ times the original row t and τ times the original row k, that row k of the product is another linear combination of those original rows, and that all other rows are unchanged. Explicitly, if σ and τ satisfy the above equation, then for 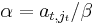 and
and 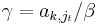 (which divisions are possible by the definition of β) one has
(which divisions are possible by the definition of β) one has
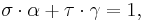
so that the matrix
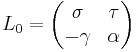
is invertible, with inverse
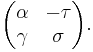
Now L can be obtained by fitting 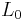 into rows and columns t and k of the identity matrix. By construction the matrix obtained after left-multiplying by L has entry β at position (t,jt) (and due to our choice of α and γ it also has an entry 0 at position (k,jt), which is useful though not essential for the algorithm). This new entry β divides the entry
into rows and columns t and k of the identity matrix. By construction the matrix obtained after left-multiplying by L has entry β at position (t,jt) (and due to our choice of α and γ it also has an entry 0 at position (k,jt), which is useful though not essential for the algorithm). This new entry β divides the entry 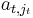 that was there before, and so in particular
that was there before, and so in particular 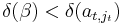 ; therefore repeating these steps must eventually terminate. One ends up with a matrix having an entry at position (t,jt) that divides all entries in column jt.
; therefore repeating these steps must eventually terminate. One ends up with a matrix having an entry at position (t,jt) that divides all entries in column jt.
Step III : Eliminating entries
Finally, adding appropriate multiples of row t, it can be achieved that all entries in column jt except for that at position (t,jt) are zero. This can be achieved by left-multiplication with an appropriate matrix. However, to make the matrix fully diagonal we need to eliminate nonzero entries on the row of position (t,jt) as well. This can be achieved by repeating the steps in Step II for columns instead of rows, and using multiplication on the right. In general this will result in the zero entries from the prior application of Step III becoming nonzero again.
However, notice that the ideals generated by the elements at position (t,jt) form an ascending chain, because entries from a later step always divide entries from a previous step. Therefore, since R is a Noetherian ring (it is a PID), the ideals eventually become stationary and do not change. This means that at some stage after Step II has been applied, the entry at (t,jt) will divide all nonzero row or column entries before applying any more steps in Step II. Then we can eliminate entries in the row or column with nonzero entries while preserving the zeros in the already-zero row or column. At this point, only the block of A to the lower right of (t,jt) needs to be diagonalized, and conceptually the algorithm can be applied recursively, treating this block as a separate matrix. In other words, we can increment t by one and go back to Step I.
Final step
Applying the steps described above to the remaining non-zero columns of the resulting matrix (if any), we get an 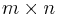 -matrix with column indices
-matrix with column indices  where
where 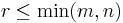 . The matrix entries
. The matrix entries 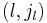 are non-zero, and every other entry is zero.
are non-zero, and every other entry is zero.
Now we can move the null columns of this matrix to the right, so that the nonzero entries are on positions 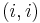 for
for 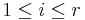 . For short, set for the element at position .
. For short, set for the element at position .
The condition of divisibility of diagonal entries might not be satisfied. For any index 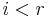 for which
for which 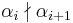 , one can repair this shortcoming by operations on rows and columns
, one can repair this shortcoming by operations on rows and columns  and
and 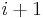 only: first add column to column to get an entry
only: first add column to column to get an entry 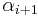 in column i without disturbing the entry at position , and then apply a row operation to make the entry at position equal to
in column i without disturbing the entry at position , and then apply a row operation to make the entry at position equal to 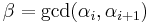 as in Step II; finally proceed as in Step III to make the matrix diagonal again. Since the new entry at position
as in Step II; finally proceed as in Step III to make the matrix diagonal again. Since the new entry at position 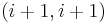 is a linear combination of the original
is a linear combination of the original 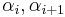 , it is divisible by β.
, it is divisible by β.
The value  does not change by the above operation (it is δ of the determinant of the upper
does not change by the above operation (it is δ of the determinant of the upper  submatrix), whence that operation does diminish (by moving prime factors to the right) the value of
submatrix), whence that operation does diminish (by moving prime factors to the right) the value of
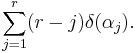
So after finitely many applications of this operation no further application is possible, which means that we have obtained 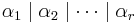 as desired.
as desired.
Since all row and column manipulations involved in the process are invertible, this shows that there exist invertible and -matrices S, T so that the product S A T satisfies the definition of a Smith normal form. In particular, this shows that the Smith normal form exists, which was assumed without proof in the definition.
Applications
The Smith normal form is useful for computing the homology of a chain complex when the chain modules of the chain complex are finitely generated. For instance, in topology, it can be used to compute the homology of a simplicial complex or CW complex over the integers, because the boundary maps in such a complex are just integer matrices. It can also be used to prove the well known structure theorem for finitely generated modules over a principal ideal domain.
Example
As an example, we will find the Smith normal form of the following matrix over the integers.
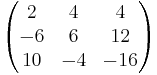
The following matrices are the intermediate steps as the algorithm is applied to the above matrix.
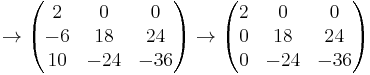
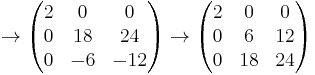
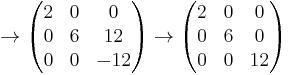
So the Smith normal form is

and the elementary divisors are 2, 6 and 12.
Similarity
The Smith normal form can be used to determine whether or not matrices with entries over a common field are similar. Specifically two matrices A and B are similar if and only if the characteristic matrices 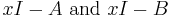 have the same Smith normal form.
have the same Smith normal form.
For example, with
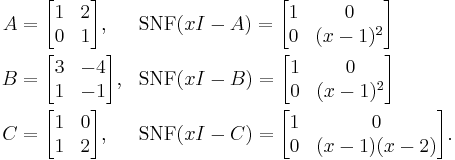
A and B are similar because the Smith normal form of their characteristic matrices match, but are not similar to C because the Smith normal form of the characteristic matrices do not match.
References
- H.J.S. Smith, "On systems of linear indeterminate equations and congruences" , Collected Math. Papers , 1 , Chelsea, reprint (1979) pp. 367–409
See also
- Canonical form
- Henry John Stephen Smith (1826 – 1883), whose name is attached to the Smith normal form
External links
- Thomas Heye's GFDL Smith normal form article at PlanetMath
- GFDL Example of Smith normal form at PlanetMath